
Verktyget Edyson
Per Fallgren, doktorand vid avdelningen för tal, musik och hörsel vid KTH, skriver om verktyget Edyson utvecklat inom projektet TillTal. Inlägget är på engelska.
Edyson is a web-based framework for browsing and annotating large amounts of speech and audio data, developed within the scope of project TillTal.
It is based on the idea of deconstructing an audio file into equally sized snippets of short duration. Given a set of these short sounds one could rearrange them, and as such listen to them, in any order or manner one wants. Perhaps most importantly, the sounds do not need be ordered in a conventional 1-dimensional sequence, but could for instance be arranged along two axes according to what they sound like – as is the case of Edyson. The purpose of the process is to remove the time constraints that typically come with analyzing large audio files manually.
Given an audio file, Edyson first does two things.
- First, the audio is segmented into snippets of equal length, typically in the range of a few hundred milliseconds to a couple seconds.
- Then the short sounds are run through an algorithm that sorts the given sounds onto a 2D grid according to how they sound. Effectively this process generates a set of xy coordinates for every sound snippet.
The set of coordinates are then visualized as points in a 2D plot. Given that the described process did its job, two points, i.e. short sounds, that are now close to each other in the plot should also sound quite similar. This allows for the forming of clusters, as can be seen in the included image. If you for instance were to process a public speech that mainly contains two types of sounds, namely speech and applause, two primary clusters containing the respective sounds will form.

Speech (green) and applause (blue) separated. Colored manually.
Given the generated interface, Edyson has a list of functionalities. The most important functionality is the listening function, which allows the user to listen to the processed audio. This is done by simply hovering over a region of points using the cursor, the system then samples randomly from the selected points and plays the sounds with some overlap which produces a blend of sounds. If the user finds an interesting region they can assign a label to it by coloring the points of interest; the timeline then provides instantaneous feedback on where the colored region occurs in the original audio. Given the previously mentioned example it is now possible to also see where in the recording the speech and applause segments are occurring.
Edyson can also output any potential findings, specifically, the export function temporally reassembles every sound snippet with their respective label (color). The output can then be imported into other software for further analysis.
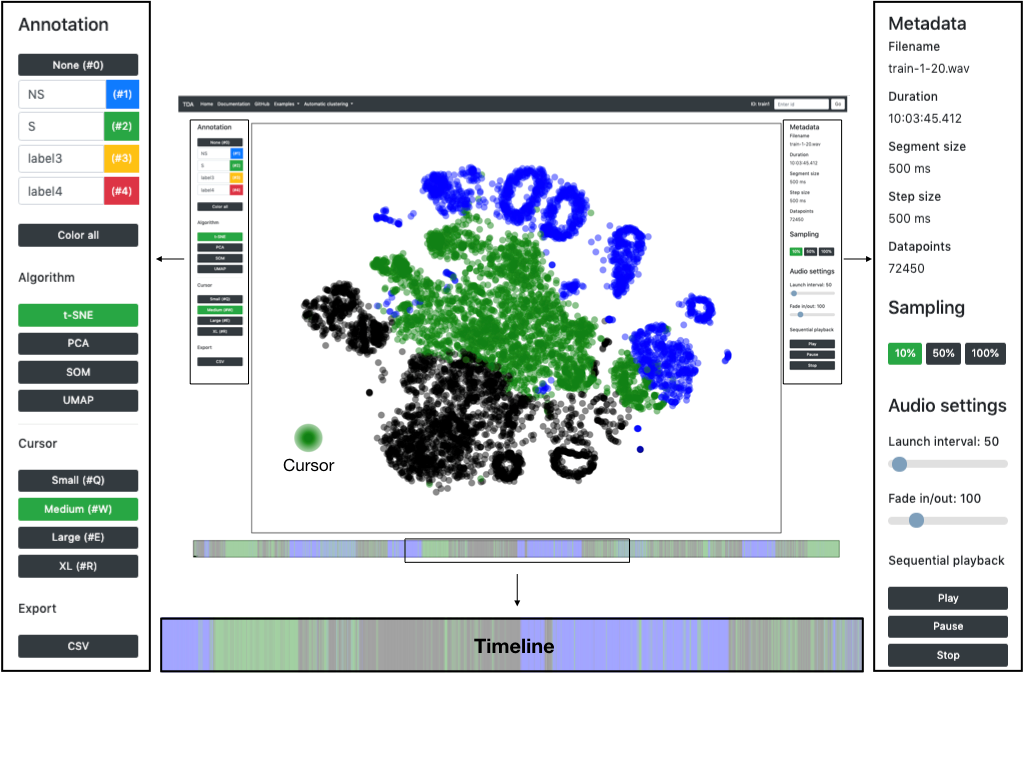
The Edyson interface
The reason for using Edyson is at least twofold. First, it is an appropriate method for browsing some audio quickly and as such a way for researchers to gain insight into the nature of their data. This is a task that might seem trivial at first, but it is often challenging given the large size of modern audio collections. As an example, the Institute of Language and Folklore in Uppsala hosts many thousands of hours of audio data. It is entirely conceivable that a lot, if not most, of these data, are not properly labeled. As is the case for other speech archives and audio collections that are potentially even bigger. Edyson allows for fast and efficient browsing of audio which greatly facilitates many tasks within research and audio analysis. Secondly, Edyson can also be used for annotation. This functionality serves to provide the user with a basic set of labels of their findings, that for instance could be refined in further analysis.
Currently Edyson is being used in the project TillTal, that aims to make cultural heritage recordings accessible for speech research. As stated above, The Institute for Language and Folklore (ISOF) is engaged in the project and hosts more than 20,000 hours of speech recordings, most of which are digitized. The technology presented here has proven to be a fruitful resource regarding the task of utilizing the large quantities of speech data at hand.
-----
Per Fallgren
PhD Student
KTH Royal Institute of Technology
Department of Speech, Music and Hearing (TMH)